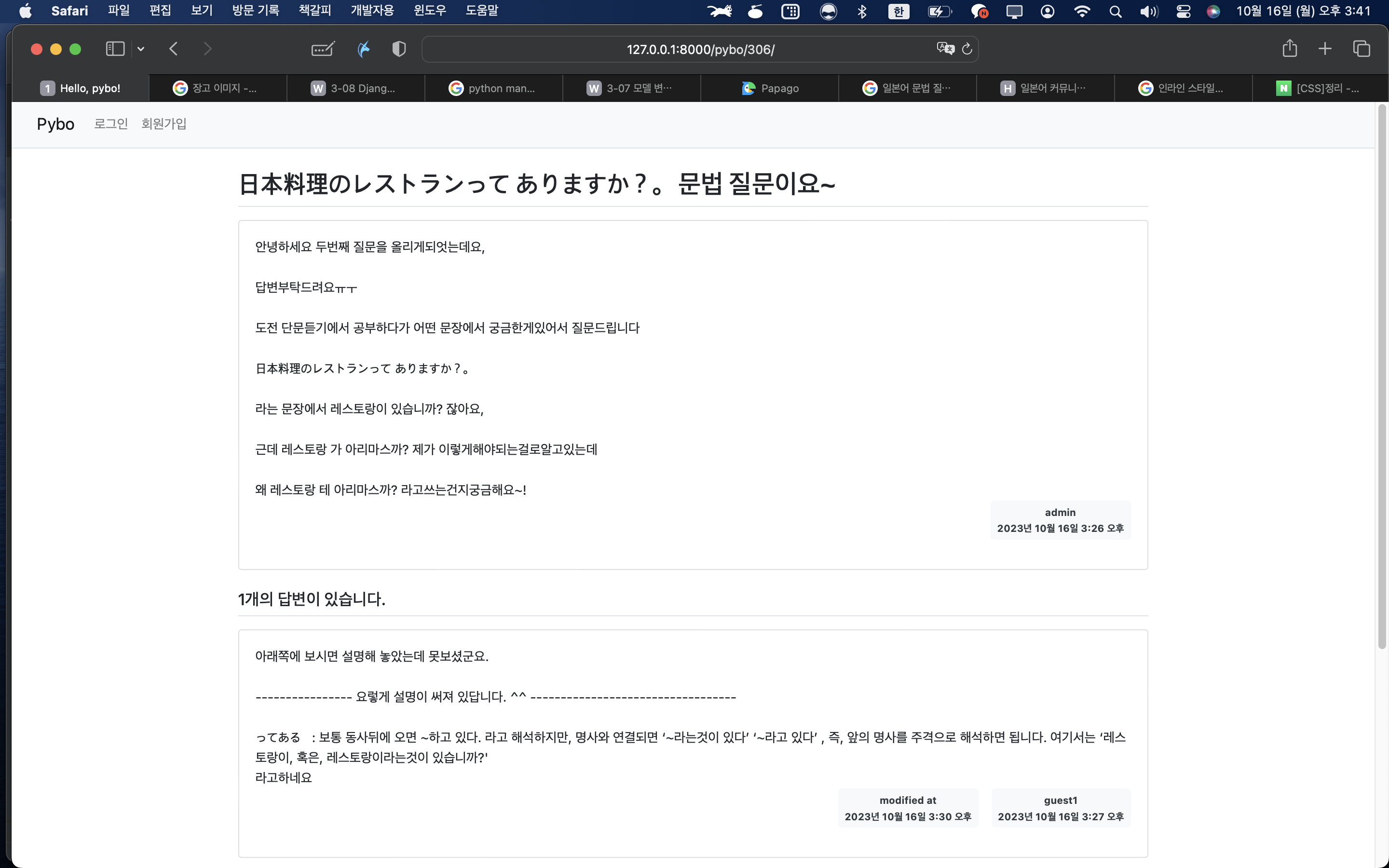
장고 프로젝트를 하다가 프로그램이 뻑이 가서 골머리를 앓았다
코드를 있는대로 붙여넣고 수정하고 하다보니 뭐가 뭔지 어디가 어딘지 알 수 없어졌다
그래서 처음부터 다시 샅샅이 살펴봐야했다
내가 짠 코드를 적용시키기 위해 워크 플로우를 다시 정리 해보아야겠다.
아래는 ocr.py 파일이다
더보기
import os
import re
# from google.cloud import vision
from google.cloud.vision_v1 import types
from google.cloud import vision_v1
from PIL import Image, ImageDraw
from django import forms
from .models import ImageModel
def Nice(image_path_test):
# 인증 설정 (서비스 계정 키 JSON 파일 경로)
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './pybo/graphic-jet-394909-3ac279e985b3.json'
# Vision API 클라이언트 초기화
client = vision_v1.ImageAnnotatorClient()
# 이미지 파일 경로
# image_path = './image/테스트단어.png' #250/20 10,30,400,150
# image_path = './image/테스트단어2.png'
# image_path = './테스트4.png'
image_path = image_path_test
# 이미지 열기
with open(image_path, 'rb') as image_file:
content = image_file.read()
# 이미지 데이터로 Image 객체 생성
image = types.Image(content=content)
#일본어만 추출
def extract_japanese(texts):
japanese_texts = []
# 일본어 문자를 포함하는 문자열을 찾기 위한 정규 표현식
pattern = re.compile(r'[\u3040-\u30FF\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF]')
for text in texts:
if pattern.search(text.description):
japanese_texts.append(text)
return japanese_texts
def remove_korean(texts):
non_korean_texts = []
# 한글 문자를 찾기 위한 정규 표현식
pattern = re.compile(r'[\uAC00-\uD7A3]')
for text in texts:
if not pattern.search(text.description):
non_korean_texts.append(text)
return non_korean_texts
# 이미지에서 텍스트 추출
# image_context = vision_v1.ImageContext(language_hints=["ja"])
response = client.text_detection(image=image)
texts = remove_korean(response.text_annotations)
# texts = response.text_annotations
def get_center(vertex1, vertex2):
"""두 꼭지점 간의 중심 좌표를 반환합니다."""
x_center = (vertex1.x + vertex2.x) // 2
y_center = (vertex1.y + vertex2.y) // 2
return x_center, y_center
def calculate_distance(point1, point2):
"""두 점 간의 거리를 계산합니다."""
return ((point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2) ** 0.5
def group_boxes(annotations, threshold_x=250, threshold_y=20): #threshold_x 값(간격)을 조절해서 한단어로 묶기
"""임계값 이내의 경계 상자들을 그룹화합니다."""
centers = [get_center(text.bounding_poly.vertices[0], text.bounding_poly.vertices[2]) for text in annotations]
groups = []
visited = set()
for i, center1 in enumerate(centers):
if i in visited:
continue
group = [i]
for j, center2 in enumerate(centers):
dx = abs(center1[0] - center2[0]) # x 좌표의 차이
dy = abs(center1[1] - center2[1]) # y 좌표의 차이
if i != j and j not in visited and dx < threshold_x and dy < threshold_y:
group.append(j)
visited.add(j)
groups.append(group)
visited.add(i)
return groups
def draw_grouped_boxes(image_path, annotations, groups, min_width=10, min_height=30, max_width=400, max_height=150):
"""그룹화된 경계 상자들을 그립니다."""
im = Image.open(image_path)
draw = ImageDraw.Draw(im)
group_texts_list = [] # 텍스트 값을 저장할 리스트 초기화
for group in groups:
min_x = min([annotations[i].bounding_poly.vertices[0].x for i in group])
min_y = min([annotations[i].bounding_poly.vertices[0].y for i in group])
max_x = max([annotations[i].bounding_poly.vertices[2].x for i in group])
max_y = max([annotations[i].bounding_poly.vertices[2].y for i in group])
width = max_x - min_x
height = max_y - min_y
if width >= min_width and height >= min_height and width <= max_width and height <= max_height:
draw.rectangle([min_x, min_y, max_x, max_y], outline='red')
# 해당 경계 상자 내의 텍스트를 추출하고 출력
group_texts = [annotations[i].description for i in group]
group_texts_combined = ''.join(group_texts)
group_texts_list.append(group_texts_combined) # 텍스트 값을 리스트에 추가
print(group_texts_list)
# print(extract_japanese(group_texts))
# im.show()
return group_texts_list # 텍스트 값이 저장된 리스트 반환
groups = group_boxes(texts)
return draw_grouped_boxes(image_path, texts, groups)
class ImageForm(forms.ModelForm):
class Meta:
model = ImageModel
fields = ['image']이 코드를 views.py에서
from .ocr import Nice처럼 ocr 파일의 Nice 함수를 임포트하고
def ocr_page(request):
texts = Nice("/Users/sim-onejin/Coding/python/projects/mysite/pybo/테스트4.png")
context = {'texts': texts}
return render(request, 'pybo/ocr.html', context)처럼 함수를 만들어준다.
texts라는 변수에 Nice함수에서 리턴 받은 값을 저장해주고 context에 넣고 랜더 시켜준다.
models.py에는
class ImageModel(models.Model):
image = models.TextField()같은 방식으로 만들어준다. 코드가 정확하진 않음 수정필요
이미지를 띄워주기 위해서는
settings.py에
STATIC_URL = "static/"
STATICFILES_DIRS = [
BASE_DIR / 'static',
os.path.join(BASE_DIR, "static"),
]pybo/url.py에
# 이미지를 업로드하자
from django.conf.urls.static import static
from django.conf import settings
urlpatterns = [
...
]
# 이미지 URL 설정
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)urlpatterns 위 아래에 위와 같은 코드를 삽입해주고 ocr.html에
<img src="../media/image.png" width="300px">를 통해 띄울 수 있다.
question_list.html에 <a href="{% url 'pybo:ocr_page' %}">link</a>로 링크를 타고 넘어가면
urls.py에 path("ocr/", views.ocr_page, name='ocr_page'), 로
views.py에
def ocr_page(request):
texts = Nice("/Users/sim-onejin/Coding/python/projects/mysite/pybo/테스트4.png")
context = {'texts': texts}
return render(request, 'pybo/ocr.html', context)
로 ocr.html을 연결시켜 띄워줄 수 있다.
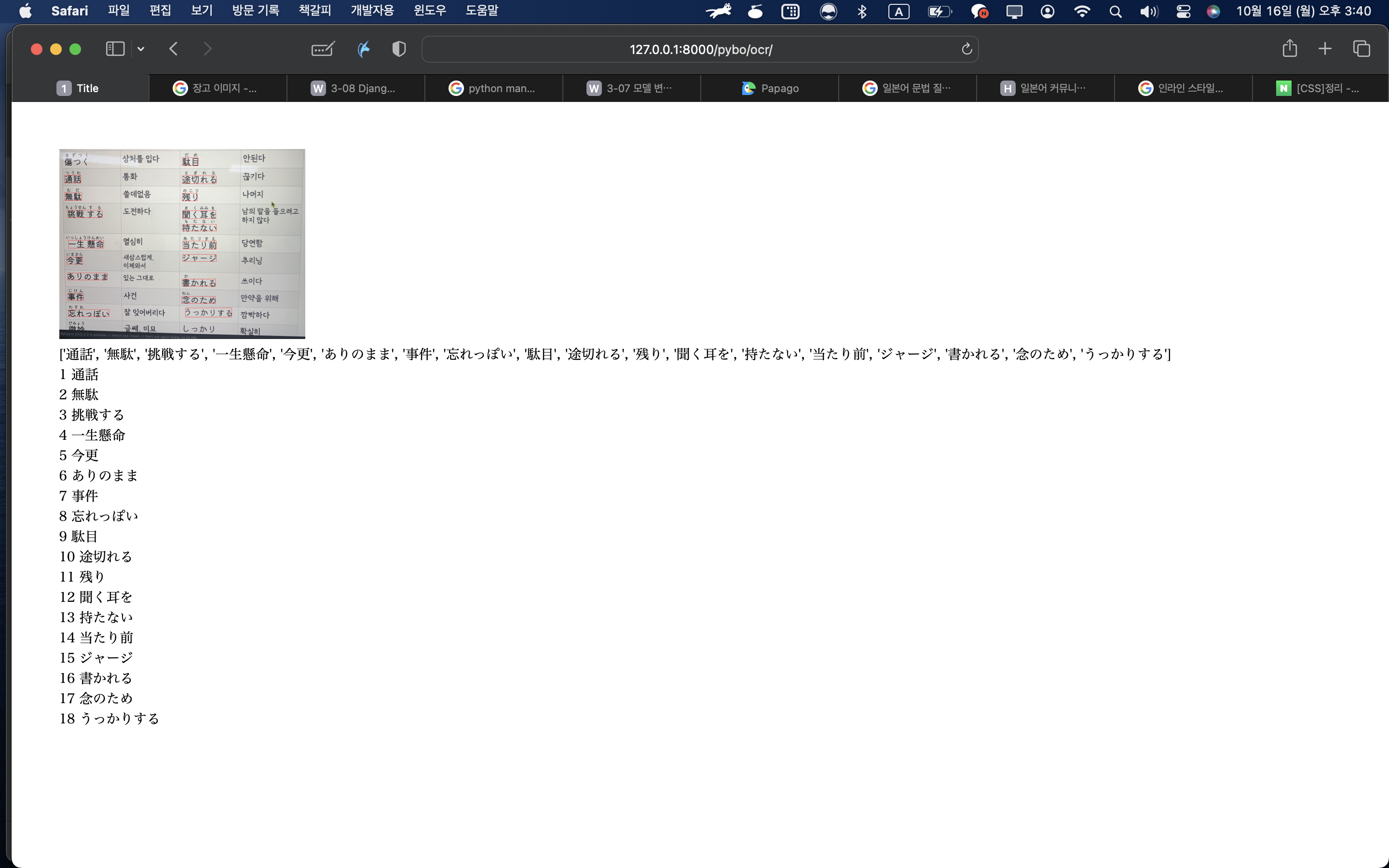
결과 이미지 이다.
AWS 서버주소: http://13.209.46.49:80
'Django' 카테고리의 다른 글
| Django 배포하기(git, AWS) (0) | 2023.10.31 |
|---|---|
| Django 사용자로부터 이미지 받고 일본어 단어 추출하기 (1) | 2023.10.30 |
| Django 0914 내가 만든 프로그램과 연계 (0) | 2023.09.14 |
| DJango Python 0823 (0) | 2023.08.29 |
| DJango Python (0) | 2023.08.16 |